




| Application Development | |
The database interface provides access to a database engine through one of Panther's database drivers. You can enter SQL statements using the SQL syntax supported by your database engine. With the database interface, you also have access to a series of commands to help you return the information to Panther variables. These commands are included in each of Panther's database drivers and can be used in either JPL procedures or C functions.
A Panther application receives two types of information from a database:
SELECT statement.
This chapter discusses how this information flows from one or more databases to variables in a Panther application, in particular the destination and format of data returned by The An application can also receive data as the result of executing a stored procedure. Since all engines do not support stored procedures, and the syntax of commands varies among those that do, refer to the Database Drivers for more information.
The information on how data is mapped to Panther variables also applies to processing in the transaction manager even though most of the examples in this chapter use the DBMS QUERY command to construct the SQL SELECT statements. For information about error and status codes, refer to Chapter 37, "Processing Application Errors."
SQL SELECT statements would be part of a client screen in a two-tier application and a service component in a three-tier application. In a three-tier application, client screens obtain database information by sending service requests to the application server. For information about writing service requests in a JetNet or Oracle Tuxedo application, refer to Chapter 5, "Defining Services in JetNet and Oracle Tuxedo Applications," in the JetNet/Oracle Tuxedo Guide.
SQL SELECT statements.
Fetching Data Using SELECT Statements |  |
When a SELECT statement is passed to an engine, Panther performs several steps before transferring data to Panther variables.
0 if there are no target variables. Refer to "Fetching Multiple Rows" for more information.The sequence above describes a SQL SELECT that writes database column values to occurrences of a widget, JPL variable, or LDB variable. You can also direct the results of a SELECT to a text file or concatenate all the values in a row to a single Panther variable. Refer to page 29-19 for more information.
Targets for a SELECT Statement | |
For an application to retrieve data from a database, there must be an unambiguous mapping between a selected database column and its Panther destination. There are two ways of associating Panther target variables with database columns.
By default when executing a to return values to Panther variables, the table The application can have a Panther destination variable for none, some, or every named column in the Panther also permits the use of the * in the Using automatic mapping, Panther looks for a variable for each column in the table Automatic Mapping
SELECT statement, Panther will search for variables with the same names as the specified columns. These Panther variables can be widgets, JPL variables, or LDB variables. For the statement,
DBMS QUERY SELECT title_id, name, pricecat FROM titlestitles must have at least three columns: title_id, name, and pricecat. If any of these columns does not exist in the table titles, the engine returns an error.
SQL SELECT statement. To return the values of all three columns to the application, there must be a Panther variable for each column. The variables can be named title_id, name and pricecat. If one of these variables does not exist, Panther ignores the values belonging to that particular column.
SELECT statement,
DBMS QUERY SELECT * FROM titlestitles. Columns without matching variables are simply ignored. This is not treated as an error.
using qualified column names
You can use one or more qualified column names in
SELECTstatements. For example,DBMS QUERY SELECT titles.title_id, titles.name,
titles.pricecat FROM titlesThe Panther targets, however, must be given unqualified names:
title_id,name, andpricecat.
When using automatic mapping, the case of the Panther variable names should correspond to the case flag used in the engine initialization. If the engine's case flag is
DM_FORCE_TO_LOWER_CASE, the Panther variables for aSELECTstatement should have lower case names. If the case flag isDM_FORCE_TO_UPPER_CASE, the Panther variables should have upper case names. If the case flag isDM_PRESERVE_CASE, the Panther variables should match the exact case of the database columns. For information on a particular engine's case flag, refer to the Database Drivers.Aliasing
Aliasing is used when automatic mapping is inconvenient or impossible to use. In particular, aliasing is necessary when selecting any of the following:
- A column whose name is not a legal Panther variable name.
- A column whose name conflicts with other Panther variable names in the application.
- A computed column or the result of an aggregate function (e.g.,
COUNT,SUM,AVG,MAX,MIN).
Aliasing is not limited to these conditions. Any or all columns can be aliased if desired. For example, you can alias a column if its name is not descriptive or if you wish to name target variables for a particular table and column.
Panther provides the command DBMS ALIAS to specify aliases. On some engines, you can also use the engine's
SELECTsyntax to specify aliases.Using DBMS ALIAS
DBMS ALIAS is associated with a
SELECTcursor, either a named cursor or the defaultSELECTcursor. If a cursor is not named, the aliases affect allSELECTstatements executed with the default cursor. You can assign aliases by name or by position. The following syntax aliases a column name to a Panther variable:DBMS [WITH CURSORcursor] ALIAScolumn1pantherVar1 \
[,column2pantherVar2... ]The following syntax aliases a column position to a Panther variable:
DBMS [WITH CURSORcursor] ALIASpantherVar1[,pantherVar2... ]Only one DBMS ALIAS
statement can apply at any one time to any named or default cursor. In that statement, either named or positional aliasing can be used, but both forms can not be used in a singleDBMS ALIASstatement.
To turn off aliasing, execute DBMS ALIAS without any arguments. Again, if a cursor name is given, aliasing is turned off on the named cursor. If no cursor name is given, aliasing is turned off on the default cursor.
The case of the column names in the DBMS ALIAS statement should correspond to the case flag used in the engine initialization. If the engine's case flag is
DM_FORCE_TO_LOWER_CASE, the column names should be in lower case. If the case flag isDM_FORCE_TO_UPPER_CASE, the column names should be upper case. If the case flag isDM_PRESERVE_CASE, the column names should use the exact case of the database columns. The case ofpantherVarshould always match the exact case of the Panther variable name. For information on a particular engine's case flag, refer to the Database Drivers.If an application aliases a column to a Panther variable that does not exist, Panther ignores the column's values. This is not treated as an error.
Aliasing by Column Names
First, consider an example that aliases column names to Panther variables. For example:
DBMS ALIAS first_name first, last_name last
DBMS QUERY SELECT cust_id, first_name, last_name FROM customersPanther writes the values from the column
first_nameto the variablefirstand it writes the values of columnlast_nameto the variablelast. Since no alias was given forcust_id, it maps it to a variable of the same name. This is illustrated in Figure 29-1.
Figure 29-1 The mapping of a SELECT statement when aliases are used.
Aliases can also be given after declaring a named cursor. For example:
DBMS DECLARE cust_cursor CURSOR FOR SELECT \
cust#, member_date, member_status FROM customers
DBMS WITH CURSOR cust_cursor ALIAS "cust#" cust_num
DBMS WITH CURSOR cust_cursor EXECUTESince
cust#is not a legal Panther variable name, the application must declare an alias for the column if it is to receive the column's value. Before executing the cursor, the application aliases columncust#to variablecust_num. The cursor keeps this alias until the application turns it off with DBMS ALIAS or closes the cursor with DBMS CLOSE CURSOR. If a column name is not a valid Panther identifier, enclose it in quote characters; this ensures that Panther parses it correctly.Aliasing by Column Positions
Consider an example that uses positional aliases. For example:
DBMS ALIAS min_rent, max_rent, avg_rent
DBMS QUERY SELECT MIN(num_rentals), MAX(num_rentals), AVG(num_rentals) FROM customersPanther writes the aggregate function values to the alias variables. The value of
MIN(num_rentals)is written to the variablemin_rent,MAX(num_rentals)is written to the variablemax_rent, andAVG(num_rentals)is written to the variableavg_rent. There is no automatic mapping available for values resulting from calculations or aggregate functions. If the application had not declared aliases, the values would not be written to Panther variables.Of course, the application should turn off the positional aliases when it is finished. If it does not turn them off before executing the next
SELECTstatement on that cursor, Panther will attempt to write the values of the first three columns to the three positional alias variables. If those variables are no longer available, Panther will ignore the first three columns in the select set.Aliasing with the Engine's SELECT Syntax
Many engines support aliasing in their
SELECTstatement syntax. In interactive mode, this permits the user to specify for a view a column heading that is different than the database column name. Typically, the syntax isSELECTcolumn1 heading1, column2 heading2...FROMtableIn interactive mode, the values of
column1are placed under the headingheading1, and the values ofcolumn2are places under the headingheading2. In this syntax, a space separates a column from its alias, and a comma separates the column-alias set from the next column or column-alias set. Some engines might support another syntax. Refer to your database engine documentation for details.If an engine supports aliasing in a
SELECTstatement, Panther will also support it. You can follow the syntax of the engine, replacing heading with the name of the appropriate Panther variable.For example, if the syntax shown above is supported by the engine, than the following could be used in a Panther application,
DBMS QUERY SELECTtitle_idid,name,pricecatprice
FROMtitlesWhen this statement is executed, the DBMS tells Panther that the columns
id,name, andpricewere selected. Panther looks for variables with those names. If there is a variabletitle_idavailable, thisSELECTstatement will not write to it because the engine has aliased it toid.Although this form is supported, using DBMS ALIAS is recommended, especially for applications accessing more than one engine. Panther provides identical support for
DBMSALIASon all engines.
Fetching Multiple Rows
Since a select set often contains more than one row, you must specify how many rows to fetch at one time. In addition, the application architecture determines whether you can fetch additional rows from the database. In two-tier applications with a direct connection to the database, DBMS CONTINUE commands can be used to fetch subsequent rows. In three-tier applications, all rows must be fetched at once.
Determining the Number of Occurrences
Panther uses the following guidelines in determining the number of rows to fetch:
- If an occurrence number was specified with a target variable name, only one row is fetched.
- If using browse mode, only one row is fetched. (Refer to Database Drivers to see if the engine supports browse mode.)
Be careful of LDB variables that are unintentional targets of a
SELECTespecially when using the wild card * in aSELECTor when executing aSELECTin a screen entry function.For example, consider an application using the wild card:
DBMS QUERY SELECT * FROM tableThe application has onscreen widgets for some of the columns in the table. The LDB, however, contains an entry with the name of one of these unrepresented columns. If the onscreen fields have 20 occurrences and the LDB entry has 5 occurrences, only five rows will be fetched.
Also, consider an application that executes a
SELECTin a screen entry function. By default, Panther first searches the LDB and then the screen for Panther variables when executing screen entry functions. Therefore, if a variable is represented both as an onscreen field and as an LDB variable, a screen entry function will write to the LDB variable before the LDB merge writes to the onscreen field. If the LDB variable and the field do not have the same number of occurrences, data is lost or appears lost when the LDB merge updates the screen fields.Scrolling Through a SELECT Set
Most applications must be capable of handling a fluctuating number of data rows. Based on the type of data selected and the hardware in use, you can use either or both types of scrolling—scrolling arrays or non-scrolling arrays.
If scrolling arrays are used as the destination variables of a
SELECTstatement, the entire select set is fetched in a single step. To view the rows, press the page up and page down keys (logical keysSPGUandSPGD).Otherwise, the application uses single-element fields or non-scrolling arrays as the destination variables of a
SELECTstatement. The select set is fetched incrementally. To permit the user to scroll backward and forward in the set, the application must set up a method to execute the Panther scrolling commands.The two methods are described in detail below.
Using Scrolling Arrays
Scrolling arrays are useful for small to mid-sized sets. Set the scrolling property (under Geometry) to
PV_YES. Set the # of Occurrences (num_occurrences) property or leave it blank, in which case the number of occurrences is determined by themax_fetchesproperty. By default, this property is set to 1000. Because the application must keep the entire select set in memory, you might want to lower the maximum number of occurrences depending on the platform or for aSELECTinvolving many columns.With this approach, you create large scrolling arrays with more occurrences than the number of rows you expect to be in the select set. When the
SELECTis executed at runtime, there is no penalty for unused occurrences; Panther allocates only whatever memory is needed to hold the returned rows. Therefore, a Panther screen might contain variables each with 10 elements and 1000 occurrences. If a select set contained only 75 rows, Panther would allocate memory for 75 occurrences in each of the variables; it would not allocate memory for the 925 unused occurrences.There are several ways of verifying that the arrays actually contained enough occurrences to hold the entire select set. Most often the application examines the value of the global variable @dmretcode. Panther writes a no-more-rows status code to this variable when the engine signals that it has returned all requested rows. The value of this variable can be examined after a
SELECTstatement.Refer to Table 37-1 for more information on
@dmretcodeand related variables. An example procedure is shown below:proc select_all
DBMS QUERY SELECT cust_id, first_name, last_name, member_status
FROM customers
if @dmretcode == DM_NO_MORE_ROWS
msg esmg "All rows returned."
else
msg emsg "Application could not display all customers."
returnThis approach is very easy to use. Since all the rows are fetched at once, the application makes only one request of the database server and it is free to use the default
SELECTcursor to make new selects.It is not the best method for large
SELECTsets. If the application is too slow displaying the data or is sluggish after the rows have been fetched, you should consider using non-scrolling arrays or some other alternative scroll driver.Using Non-scrolling Arrays
Non-scrolling arrays are useful for mid-sized to large select sets. Panther does not impose any limit on the number of rows that can be displayed with this method.
For widgets to be non-scrolling arrays, the
array_sizeproperty is set to > 1 and scrolling is set toPV_NO. At least two JPL procedures are needed to view the select set. The first procedure executes theSELECTstatement and fetches the first screenful of rows. The second procedure executes a DBMS CONTINUE to fetch the next screenful of rows from the select set. The second procedure might be executed many times before the user sees all the rows.Notes: In multi-user environments, you should know how the engine ensures read consistency—the guarantee that data seen by a
SELECTdoes not change during statement execution. The engine might be using rollback segments or shared locks to provide read consistency. Since a shared lock prevents other users from updating locked rows, applications on these engines should release the lock as soon as possible.For example, the current screen has widgets named for the columns in the table titles. Each widget has
array_sizeset to 5. The application uses procedures like the following to select data from a table and view additional rows:proc select_video
DBMS QUERY SELECT * FROM titles
returnproc continue_select
DBMS CONTINUE
returnas well as control strings like the following to execute the procedures:
PF1=^select_video
PF2=^continue_selectAssume that table titles contains 12 rows. When you press the PF1 key, the application executes the JPL procedure
select_videoand writes rows 1 through 5 to the screen. If you press PF2, the application executes the procedurecontinue_selectwhich clears the arrays and writes rows 6 through 10 to the screen. If you press PF2 again, the application executescontinue_selectagain which clears the arrays and writes rows 11 and 12 to the screen. If you press PF2 a third time, the application does nothing because there are no more rows in the select set.Non-scrolling arrays use less memory than scrolling arrays. With non-scrolling arrays, the application needs only enough memory for the rows displayed on screen. The other rows are buffered either in a binary disk file or by the database server. With large select sets, this approach often improves the application's performance and response time.
This approach requires a little more work. The application needs procedures to handle the scrolling and possibly the remapping of cursor control keys. Also, the method restricts the
SELECTcursor. If the application needs to perform otherSELECTstatements while scrolling through this set, the application must declare named cursors to execute additional SQL statements.Scrolling Commands
In addition to DBMS CONTINUE, an application can simulate scrolling through a
SELECTset by using the following commands:
Scrolls to the last screenful of rows
Does the same as DBMS CONTINUE
Scrolls to the first screenful of rows
Scrolls up a screenful of rows
Some engines have native support for these commands. For example, the engine might buffer the rows in memory on the server. However, Panther also provides its own support for these commands. Use DBMS STORE FILE to set up a continuation file for a named or default
SELECTcursor. When it is used, Panther buffersSELECTrows in a temporary binary file. The syntax of the command is:DBMS [WITH CURSORcursor] STORE FILE [filename]The command is supported on all engines. To select and view data, an application uses procedures like the following:
proc select_video
DBMS STORE FILE vidlist
DBMS QUERY SELECT * FROM titles
returnproc scroll_down
DBMS CONTINUE
returnproc scroll_up
DBMS CONTINUE_UP
returnproc scroll_top
DBMS CONTINUE_TOP
returnproc scroll_end
DBMS CONTINUE_BOTTOM
returnThen, you attach these procedures to push buttons or function keys. The following example attaches the procedures to function keys:
PF1=^select_video
PF2=^scroll_down
PF3=^scroll_up
PF4=^scroll_top
PF5=^scroll_endUsing the same number of rows and occurrences as earlier, when you press the PF1 key, the application executes the JPL procedure
select_videoand writes rows 1 through 5 to the screen. If you press PF2, the application executes the procedurescroll_downwhich clears the arrays and writes rows 6 through 10 to the screen. If you press PF3, the application executesscroll_upwhich clears the arrays and writes rows 1 through 5 to the screen. If you press PF5 the application executesscroll_endwhich clears the arrays and writes the last 5 rows in theSELECTset, rows 8 through 12, to the screen.Remapping Logical Keys for Scrolling
Instead of using function keys or push buttons to call the JPL procedures which execute the Panther scrolling commands, you might prefer the standard page up and page down keys to the PF keys. The values of the logical keys
SPGUandSPGDcan be reassigned with the Panther library function sm_keyoption. Therefore, the application might use an entry and exit function to change howSPGUandSPGDwork on a screen or in a field. The entry function callssm_keyoptionso that SPGD acts like the function key that calls the scroll up procedure, and callssm_keyoptionso thatSPGUacts like the function key that calls the scroll down procedure. The exit function callssm_keyoptionto restore the default behavior.An example of this behavior in a widget entry and exit function is shown below. The widget's
entry_functionandexit_functionproperties are set toentry_exitwhich callssm_keyoption. The function keysAPP1andAPP2are set to call the JPL proceduresscroll_upandscroll_downdescribed above. When you click on the widget, the standard page up and page down keys can be used to scroll through the data.// APP1=^scroll_up
// APP2=^scroll_downproc entry_exit(f_no f_data, f_occ, f_flag)
if (f_flag & K_ENTRY)
{
call sm_keyoption (SPGD, KEY_XLATE, APP1)
call sm_keyoption (SPGU, KEY_XLATE, APP2)
}
else if (f_flag & K_EXIT)
{
call sm_keyoption (SPGU, KEY_XLATE, SPGU)
call sm_keyoption (SPGD, KEY_XLATE, SPGD)
}
returnControlling the Number of Rows Fetched
If you use widget or LDB arrays as the destinations of a
SELECT, you can specify the maximum number of rows to fetch and the first occurrence to write to in the array destination. The command isDBMS [ WITH CURSORcursor-name] OCCURint[ MAXint]DBMS [ WITH CURSORcursor-name] OCCUR CURRENT [ MAXint]Refer to page 11-38 in the Programming Guide for more information on this command.
Choosing a Starting Row in the SELECT Set
You can also change the number of rows fetched by using the command
DBMS [ WITH CURSORcursor-name] STARTintThe command tells Panther to read and discard
int- 1 rows before writing the rest of the select set to Panther variables.Refer to page 11-50 in the Programming Guide for more information on this command.
Format of Select Results
Before writing a database column value to a Panther variable occurrence, Panther determines the data type of the database column.
In all cases, if the value equals the engine's null (for example,
NULL), Panther clears the variable. If the variable has thenull_fieldproperty set toPV_YES, Panther automatically converts the null string to the one assigned by the widget's property specification.If any value is longer than the variable, the data is truncated.
Character Column
If a column has a character data type, the value is simply written to the target variable. If the variable has the
word_wrapproperty set toPV_YESor the justification property set toPV_RIGHT, the property is applied.Date-time Column
If a column has a date data type, Panther formats the value before writing it to a Panther variable. If the variable has a date-time specification, Panther uses it. If the variable does not, Panther uses the format assigned to the message file entry
SM_0DEF_DTIME. By default, the entry isSM_0DEF_DTIME = %m/%d/%2y %h:%0MFor example, April 1, 2015 10:05:03 would be formatted as 4/1/15 10:05. When the message file default is used, Panther assumes a 12-hour clock.
For information on date and time formats, refer to page 10-17 in the Using the Editors.
Numeric Column
If a column has an integral type, Panther converts the value to a long. Panther then converts the value to ASCII and writes it to the variable, truncating any data longer than the destination variable. If
data_formattingis set toPV_NUMERICandc_typeis set toPV_DEFAULT, the numeric format is applied to the data.If a column has a real type, Panther converts the value to a double. Before writing the value to a Panther variable, Panther examines the widget's Data Formatting and C Type properties to help determine the precision.
- Numeric format (
data_formatting = PV_NUMERIC) and default data type (c_type = PV_DEFAULT)
If the value is less precise than that specified in the Min Decimal (
min_decimals) property (defines the minimum number of decimal places), the value is padded to the minimum number of decimal places. If the value is more precise, it is rounded or adjusted to the numeric type's maximum number of decimal places (max_decimalsproperty). The Rounding (rounding) property specification (round up, round down, or adjust) of the numeric format is applied.- None numeric data (
data_formatting = PV_NONE) and the data type is either float, double, integer, long integer, short integer (c_type = PV_FLOAT | PV_DOUBLE | PV_INT | PV_LONG_INT | PV_SHORT_INT)
If the C type is one of the integer types, the value is adjusted by standard rounding to 0 places. If the C type is float or double, the value is padded or adjusted to the type's precision.
- Data Formatting, C Type and Precision properties conflict
- If the value is less precise than the numeric format's number of decimal places (
min_decimals), the value is padded to the number of decimal places specified.
- If it uses the C type precision specification, it adjusts by standard rounding to the precision.
- None numeric data (
data_formatting = PV_NONE) and a default data type (c_type = PV_DEFAULT).
Refer to page 10-20 in the Using the Editors for more information on currency formats.
Binary Columns
If a column has an binary data type, Panther sets the column type to be
DT_BINARY. Before writing data to the widget, Panther checks thec_typeproperty. If the setting isPV_HEX_DEC, then Panther converts the binary data to a hexadecimal string. Otherwise, Panther passes the binary data as is.Generally, binary data is fetched either into variables declared with DBMS BINARY or into widgets with a
c_typeproperty ofPV_HEX_DEC. Otherwise, incorrect binding might result.Fetching Unique Column Values
By default, when a column is selected, Panther returns all values. There is also a command for displaying only a column's unique values,
DBMS [ WITH CURSORcursor-name] UNIQUEcolumn[,column... ]Panther replaces a repeating value with an empty string.
This command is useful if an application is selecting values from a table which uses two or more columns as the primary key. For example, if the table projects has the columns
project_id,staff,task_codeand the columnsproject_idand staff constitute the primary key, an application could suppress the repeating values in one of the columns of the primary key to improve readability on the screen. Figure 29-2 illustrates the data in the project table.
Figure 29-2 The primary key of the projects table is (project_id, staff).
The following commands select the data and format it to suppress repeating values:
DBMS DECLARE proj_cur CURSOR FOR \
SELECT * FROM projects ORDER BY project_id
DBMS WITH CURSOR proj_cur UNIQUE project_id
DBMS WITH CURSOR proj_cur EXECUTEFigure 29-3 is a sample screen displaying the results.
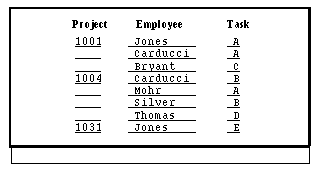
Figure 29-3 The Panther layout is easier to read than the table layout.
Refer to page 11-54 in the Programming Guide for more information.
Redirecting Select Results to Other Targets
If you need other destinations for
SELECTstatements, DBMS CATQUERY allows you to concatenate a full result row and write it to either a text file or to a Panther variable:DBMS [WITH CURSORcursor] CATQUERY TO FILENAMEfile \[SEPARATOR "text"] [HEADING [ON | OFF] ]DBMS [WITH CURSORcursor] CATQUERY TOpantherVar\
[SEPARATOR "text"] [HEADING [ON | OFF] ]There is also a command for formatting the results,
DBMS [WITH CURSORcursor-name] FORMAT [column]formatFor more information on these commands, refer to page 11-10 and to page 11-36 in the Programming Guide.